ГЛАВА 1

Основная информация о технологии видеокодирования: краткая историческая справка, основные этапы видеокодирования, основные алгоритмы кодирования в стандартах AVC/H.264 и HEVC/H.265.
Сложно представить сейчас область человеческой деятельности, в которую бы, так или иначе, не проникло цифровое видео. Мы смотрим его по телевизору, на мобильных устройствах, на стационарных компьютерах, снимаем его сами цифровыми камерами, сталкиваемся с ним на автодорогах (неприятно, но факт), в магазинах, в больницах, школах и вузах, на промышленных предприятиях самых разных профилей. Как следствие, в нашу жизнь все прочнее и шире входят слова и термины, непосредственно связанные с цифровым представлением видеоинформации. Время от времени возникают и вопросы из этой области. Чем различаются и что делают различные устройства или программы, которые мы используем для кодирования/декодирования цифровых видеоданных? Какие из этих устройств/программ лучше или хуже и в чем? Что означают все эти бесконечные MPEG2, H.264/AVC, VP9, H.265/HEVC и т.д. Попробуем разобраться.
Совсем краткая историческая справка
Первый общепринятый стандарт видео компрессии MPEG2 был окончательно принят в 1996 году, после чего началось быстрое развитие цифрового спутникового телевещания. Следующим стандартом стал MPEG4 part 10 (H.264/AVC), обеспечивающий в два раза большую степень сжатия видеоданных. Он был принят в 2003 году, что стало толчком к развитию систем DVB-T/C, Интернет ТВ и к появлению разнообразных сервисов видеообмена и видеосвязи. С 2010 по 2013 годы международной группой Joint Collaborative Team on Video Coding (JCT-VC) велась интенсивная работа по созданию следующего стандарта сжатия видеоданных, названного разработчиками High Efficient Video Coding (HEVC), который обеспечил следующее двукратное увеличение степени сжатия цифровых видеоданных. Этот стандарт был утвержден в 2013 году. В этом же году принят стандарт VP9, разрабатывавшийся компанией Google, который должен был не уступать HEVC по степени сжатия видеоданных.
Основные этапы видеокодирования
В основе алгоритмов компрессии видеоданных лежит несколько простых идей. Если взять некоторую часть изображения (в стандартах MPEG2 и AVC эту часть называют макроблок), то с большой вероятностью вблизи этого участка в данном кадре или в соседних кадрах окажется участок, содержащий похожее, мало отличающееся по значениям интенсивности пикселов, изображение. Таким образом, для передачи информации об изображении в текущем участке достаточно передать только его отличие от ранее закодированного похожего участка. Процесс поиска похожих участков среди ранее закодированных изображений называют предсказанием (Prediction). Набор разностных значений, определяющих отличие текущего участка от найденного предсказания, называют остатком (Residual). Здесь можно выделить два основных типа предсказания. В первом из них значения Prediction представляют собой набор линейных комбинаций пикселов, примыкающих к текущему участку изображения слева и сверху. Такое предсказание называют пространственным (Intra Prediction). Во втором – в качестве предсказания используются линейные комбинации пикселов похожих участков изображений с ранее закодировнных кадров (эти кадры называют Reference). Такое предсказание называют временным (Inter Prediction). Для восстановления изображения текущего участка, закодированного с временным предсказанием, при декодировании необходима информация не только об остатке (Residual), но и о номере кадра, на котором находится похожий участок, и координатах этого участка.
Полученные при предсказании значения Residual, очевидно, содержат в среднем меньше информации, чем исходное изображение и, следовательно, требуют меньшего количества битов для передачи изображения. Для дальнейшего повышения степени компрессии видеоданных в системах видеокодирования используют какое-либо спектральное преобразование. Как правило, это косинус-преобразование Фурье. Такое преобразование позволяет выделить основные гармоники в остаточном двумерном сигнале Residual. Такое выделение производится на следующем этапе кодирования – квантовании. Последовательность квантованных спектральных коэффициентов содержит небольшое количество главных, больших по величине, значений. Остальные значения с большой вероятностью являются нулевыми. В результате количество информации, содержащееся в квантованных спектральных коэффициентах, оказывается существенно (в десятки раз) ниже, чем в исходном изображении.
На следующем этапе кодирования полученный набор квантованных спектральных коэффициентов, сопровождаемый информацией, необходимой для выполнения предсказаний при декодировании, подвергается энтропийному кодированию. Суть здесь заключается в том, чтобы наиболее часто встречаемым в кодируемом потоке значениям поставить в соответствие наиболее короткое кодовое слово (содержащее наименьшее количество бит). Наилучшую степень сжатия (близкую к теоретически достижимой) на этом этапе обеспечивают алгоритмы арифметического кодирования, которые в основном и используются в современных системах видеосжатия.
Из вышесказанного становятся очевидны основные факторы, влияющие на эффективность той или иной системы видеокомпрессии. Прежде всего – это, конечно, факторы, определяющие эффективность пространственного и временного предсказаний. Второй набор факторов связан с ортогональным преобразованием и квантованием, выделяющим основные гармоники в остаточном сигнале Residual. Третий – определяется объемом и компактностью представления дополнительной информации, сопутствующей Residual и необходимой для выполнения предсказаний, то есть вычисления Prediction, в декодере. Наконец, четвертый набор – факторы, определяющие эффективность заключительного этапа – энтропийного кодирования.
Проиллюстрируем возможные варианты (далеко не все) реализации перечисленных выше этапов кодирования на примере H.264/AVC и HEVC.
Стандарт AVC
В стандарте AVC основной структурной единицей изображения является макроблок – квадратная область размером 16x16 пикселей (рис. 1). При поиске наилучшего варианта предсказания кодер может выбирать один из нескольких вариантов разбиения каждого макроблока. При пространственном Intra-предсказании таких вариантов три: выполнить предсказание для всего блока целиком, разбить макроблок на четыре квадратных блока размером 8x8 или на 16 блоков размером 4x4 пикселя и выполнять предсказание для каждого такого блока независимо. Количество возможных вариантов разбиений макроблока при временном Inter-предсказании существенно богаче (рис. 1), что обеспечивает адаптацию размера и положения предсказываемых блоков к положению и форме границ движущихся в видеокадре объектов.
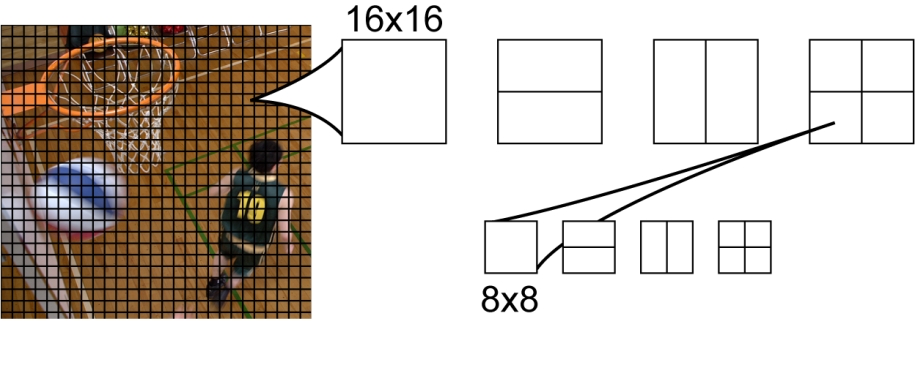
Рис. 1. Макроблоки в AVC и возможные разбиения при Inter-предсказании
В AVC для пространственного предсказания используются значения пикселов из столбца слева от предсказываемого блока и строки пикселей, расположенной непосредственно над ним (рис. 2). Для блоков размеров 4x4 и 8x8 предусмотрено 9 способов предсказания. При предсказании, называемом DC, все рассчитанные пиксели имеют одно значение, равное среднему арифметическому «пикселей-соседей», выделенных на рис. 2 толстой линией. В остальных режимах выполняется «угловое» предсказание. При этом значения «пикселей-соседей» расставляются внутри предсказываемого блока в направлениях, указанных на рис. 2. В том случае, когда предсказываемый пиксел «попадает» при движении в заданном направлении между «пикселями-соседями», для предсказания используется интерполированное значение. Для блоков размером 16x16 пикселей предусмотрено 4 способа предсказания. Один из них – это уже рассмотренное DC-предсказание. Два других соответствуют «угловым» способам, с направлениями предсказания 0 и 1. Наконец при четвертом – Plane-предсказании – значения предсказываемых пикселей определяются уравнением плоскости. Угловые коэффициенты уравнения определяются по значениям «пикселей-соседей».
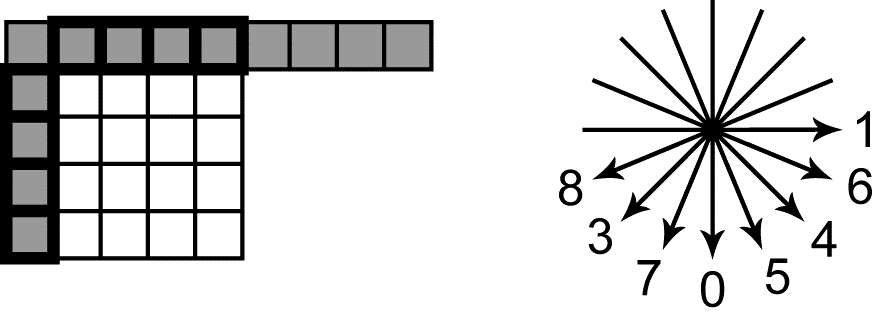
Рис. 2. «Пиксели-соседи» и угловые режимы Intra-предсказания в AVC
Временное предсказание в AVC может быть реализовано в одном из двух вариантов. Каждый из этих вариантов определяет тип макроблока (P или B). В качестве предсказания значений пикселов в P-блоках (Predictive-блоках) используются значения пикселов из области, расположенной на ранее закодированном (reference) изображении. Reference-изображения не удаляются из буфера в оперативной памяти, содержащего декодированные кадры (decoded picture buffer, DPB), до тех пор, пока они могут понадобиться для Inter-предсказания. Из индексов этих изображений в DPB формируется список (reference list). Кодер сигнализирует декодеру о номере reference-изображения в списке и о смещении области, используемой для предсказания, относительно положения предсказываемого блока (это смещение называют «вектором движения», motion vector). Смещение может быть определено с точностью до ¼ пикселя. При предсказании с нецелочисленным смещением выполняется интерполяция. Разные блоки на одном изображении могут предсказываться по областям, расположенным на разных reference-изображениях.
Как уже было сказано, следующим этапом кодирования после предсказания значений кодируемого блока и вычисления разностного сигнала Residual является спектральное преобразование. В AVC предусмотрено несколько вариантов ортогональных преобразований остаточного сигнала Residual. При Intra-предсказании всего макроблока размером 16x16 остаточный сигнал разбивается на блоки размером 4x4 пикселя, каждый из которых подвергается целочисленному аналогу дискретного двумерного 4x4 косинус-преобразования Фурье. Полученные спектральные компоненты, соответствующие в каждом блоке нулевой частоте (DC), подвергаются затем дополнительному ортогональному преобразованию Уолша-Адамара. При временном Inter-предсказании остаточный сигнал Residual разбивается на блоки размером 4x4 пикселя или 8x8 пикселей. Каждый такой блок подвергается затем соответственно 4x4 или 8x8 двумерному косинус-преобразованию Фурье (точнее его целочисленному аналогу).
На следующем этапе спектральные коэффициенты подвергаются процедуре квантования. Это приводит к уменьшению разрядности чисел, представляющих значения спектральных отсчетов, и к существенному увеличению количества отсчетов, имеющих нулевые значения. Эти эффекты обеспечивают сжатие, т.е. уменьшают количество и разрядность чисел, представляющих закодированное изображение. Оборотной стороной квантования является искажение кодируемого изображения. Понятно, что чем больше шаг квантования, тем больше степень сжатия, но и тем больше вносимые искажения.
Заключительным этапом кодирования в AVC является энтропийное кодирование, реализованное по алгоритмам контекстно-адаптивного двоичного арифметического кодирования (Context Adaptive Binary Arithmetic Coding). Этот этап обеспечивает дополнительное сжатие видеоданных без внесения искажений в закодированное изображение.
Десять лет спустя. Стандарт HEVC: что нового?
Новый стандарт H.265/HEVC является развитием методов и алгоритмов сжатия видеоданных, заложенных в H.264/AVC. Рассмотрим очень коротко основные отличия.
Аналогом макроблока в HEVC является Coding Unit (CU). Внутри каждого такого блока выбираются области для вычисления Prediction – Prediction Unit (PU). Каждая CU, кроме того, задает границы, в пределах которых выбираются области для вычисления дискретного ортогонального преобразования от остаточного сигнала Residual. Эти области носят название Transform Unit (TU). Основной отличительной чертой HEVC здесь является то, что разбиение видеокадра на CU производится адаптивно, так что есть возможность подстраивать границы CU под границы объектов на изображении (рис. 3). Такая адаптивность позволяет добиваться исключительно высокого качества предсказания и, как следствие, малого уровня остаточного сигнала Residual. Несомненным плюсом такого адаптивного подхода к разбиению кадра на блоки является также крайне компактное описание структуры разбиений. Для всей видеопоследовательности задаются максимальный и минимальный возможные размеры CU (например, 64х64 – максимально возможная CU, 8x8 – минимально). Весь кадр в порядке слева-направо, сверху-вниз покрывается максимально возможными CU. Очевидно, что для такого покрытия не требуется передачи какой-либо информации. Если в пределах той или иной CU требуется выполнить разбиение, то это индицируется одним флагом (Split Flag). Если этот флаг установлен в значение 1, то данная CU разбивается на 4 CU (при максимальном размере CU 64x64, после разбиения получаем 4 CU размером 32х32 каждая). Для каждой из полученных CU в свою очередь может быть передано значение Split Flag равное 0 или 1. В последнем случае такая CU опять разбивается на 4 CU меньшего размера. Процесс продолжается рекурсивно, пока Split Flag всех полученных CU не будет равен 0 или пока не будет достигнут минимально возможный размер CU. Вложенные CU образуют, таким образом, квадродерево (Coding Tree Units, CTU).
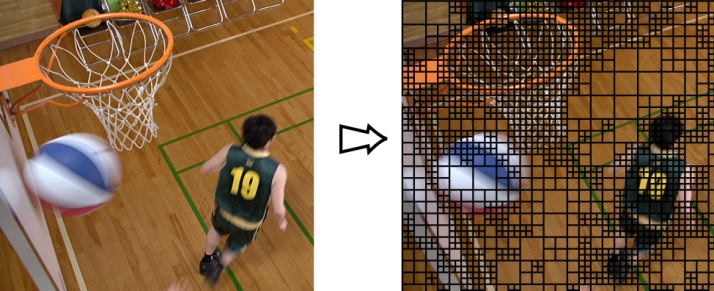
Рис. 3. Разбиение видеокадра на CU производится адаптивно
Как уже было сказано, в пределах каждой CU выбираются области для вычисления предсказания – Prediction Unit (PU). При пространственном предсказании область CU может совпадать с PU (режим 2Nx2N) или может быть разбита на 4 квадратных PU вдвое меньшего размера (режим NxN, доступный только для CU минимального размера). При временном предсказании возможны 8 вариантов разбиения каждой CU на PU (рис. 3).
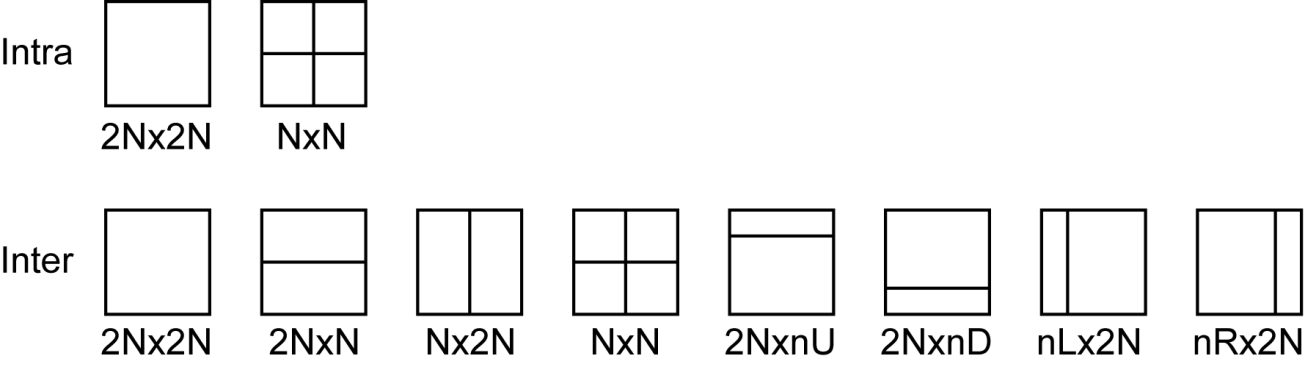
Pic. 4. Возможные разбиения Coding Unit на Prediction Unit при пространственном (Intra) и временном (Inter) режимах предсказания CU
Идея пространственного предсказания в HEVC осталась той же, что и в AVC. В качестве предсказанных значений отсчетов в блоке PU используются линейные комбинации значений пикселей-«соседей», примыкающих к блоку слева и сверху. Однако, набор способов пространственного предсказания в HEVC стал существенно богаче. Кроме Planar (аналог Plane в AVC) и DC способов каждая PU может быть предсказана одним из 33 способов «углового» предсказания. Т.е. количество направлений, в которых расставляются рассчитанные по пикселам-«соседям» значения увеличено в 4 раза.
Можно указать два основных отличия временного предсказания HEVC от AVC. Во-первых, в HEVC используются более качественные интерполяционные фильтры (с более длинной импульсной характеристикой) при расчете reference-изображений при нецелочисленном смещении. Второе отличие касается способа представления информации о reference-области, необходимой декодеру для выполнения предсказания. В HEVC введен «режим слияния» (merge mode), при котором различные PU, имеющие одинаковые смещения reference-областей, объединяются. Для всей объединенной области информация о движении (motion vector) передается в потоке один раз, что позволяет существенно сократить объем передаваемой информации.
В HEVC размер дискретного двумерного преобразования, которому подвергается остаточный сигнал Residual, определяется размером квадратной области, называемой Transform Unit (TU). Каждая CU является корнем квадродерева TU. Таким образом, TU верхнего уровня совпадает с CU. Корневая TU может быть разбита на 4 части вдвое меньшего размера, каждая из которых, в свою очередь, является TU и может быть разделена далее. Размер дискретного преобразования определяется размером TU нижнего уровня. В HEVC определены преобразования для блоков 4-х размеров: 4x4, 8x8, 16x16, 32x32. Эти преобразования являются целочисленными аналогами дискретного двумерного косинус-преобразования Фурье соостветствующего размера. Для TU размером 4x4 при Intra-предсказании предусмотрено также отдельное дискретное преобразование, являющееся целочисленным аналогом дискретного синус-преобразования Фурье.
Идеи процедуры квантования спектральных коэффициентов сигнала residual а также энтропийного кодирования в AVC и в HEVC практически идентичны.
Отметим еще один момент, о котором ранее не было сказано. Существенное влияние на качество декодированных изображений и на степень сжатия видеоданных оказывает пост-фильтрация, которой подвергаются декодированные изображения с Inter-предсказанием перед помещением их в DPB. В AVC предусмотрен один вид такой фильтрации – deblocking filter. Применение фильтра снижает блочный эффект, возникающий в результате квантования спектральных коэффициентов после ортогонального преобразования сигнала Residual.
В HEVC применяется аналогичный deblocking filter. Кроме того, предусмотрена дополнительная процедура нелинейной фильтрации, называемая Sample Adaptive Offset (SAO). На основе анализа распределения значений пикселов при кодировании определяется таблица корректирующих смещений, добавляемых к значениям части пикселов CU при декодировании.
А что в результате?
На рис. 4-7 представлены результаты кодирования нескольких видеопоследовательностей высокого (HD) разрешения двумя кодерами. Один из кодеров производит сжатие видеоданных в стандарте H.265/HEVC (на всех графиках результаты работы этого кодера отмечены как HM), второй – в стандарте H.264/AVC.
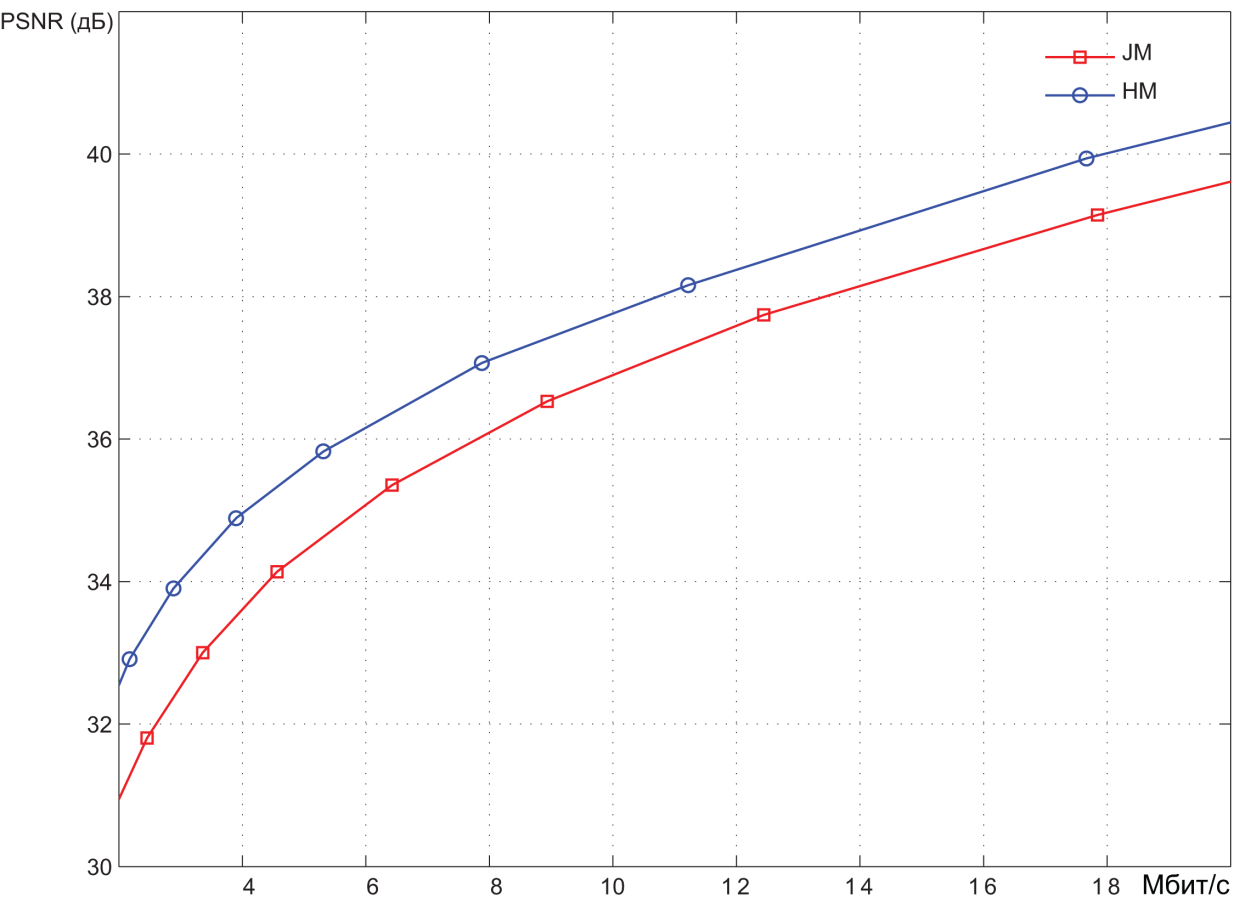
Pic. 5. Результаты кодирования видеопоследовательности Aspen
(1920x1080 30 кадров в секунду)
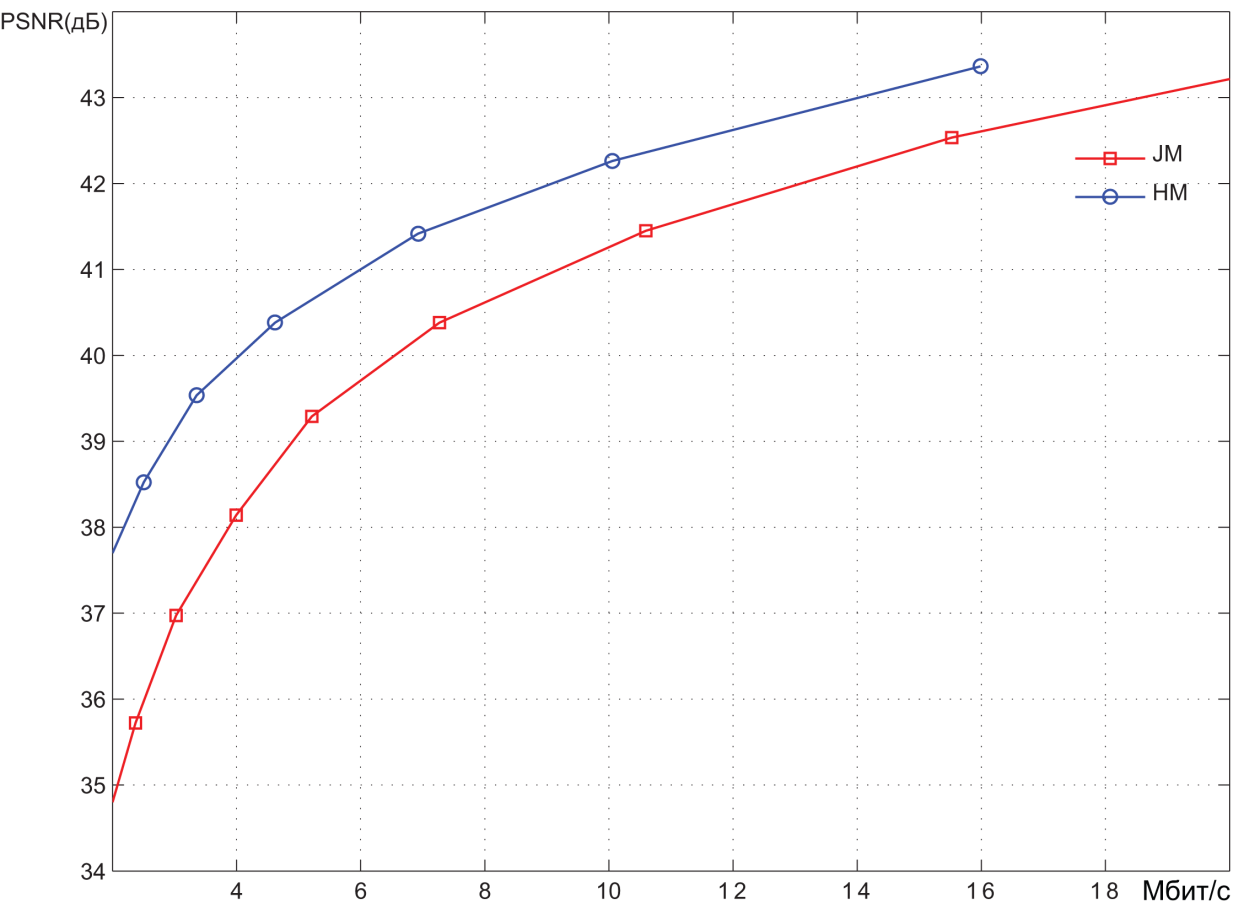
Pic. 6. Результаты кодирования видеопоследовательности BlueSky
(1920x1080 25 кадров в секунду)
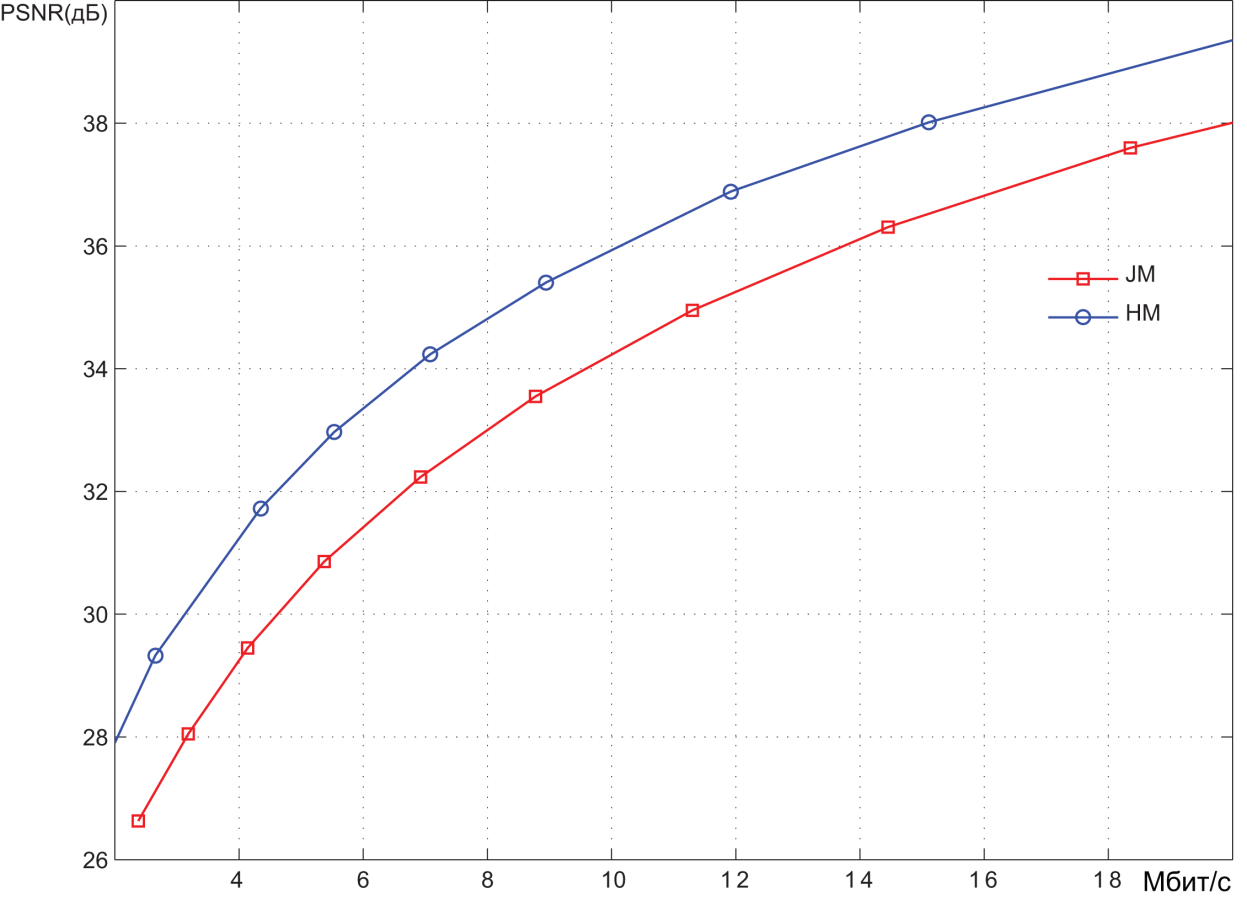
Pic. 7. Результаты кодирования видеопоследовательности PeopleOnStreet
(1920x1080 30 кадров в секунду)
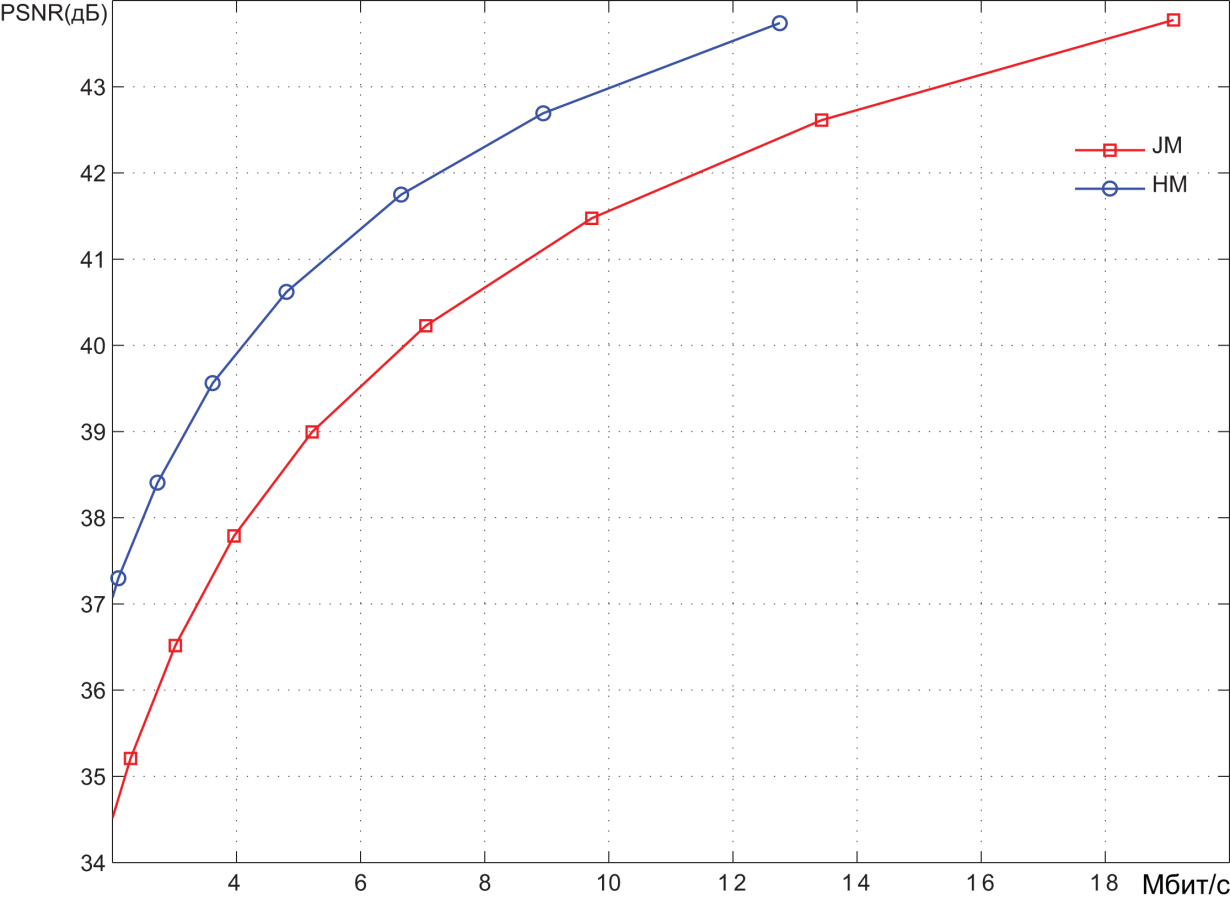
Pic. 8. Результаты кодирования видеопоследовательности Traffic
(1920x1080 30 кадров в секунду)
Кодирование производилось при различных значениях шага квантования спектральных коэффициентов и, как следствие, с различным уровнем искажений, вносимых в видеоизображения. Результаты представлены в координатах битрейт (Мбит/с) – PSNR (дБ). Значения PSNR как раз и характеризуют степень искажений. В среднем можно говорить о том, что диапазон PSNR ниже уровня 36 дБ соответствует высокому уровню искажений, т.е. низкому качеству видеоизображений. Диапазон 36 – 40 дБ соответствует среднему качеству. При значениях PSNR выше 40 дБ можно говорить о высоком качестве видео. Можно примерно оценить степень сжатия, обеспечиваемую системами кодирования. В области среднего качества битрейт, обеспечиваемый HEVC-кодером, примерно в 1.5 раза меньше битрейта на выходе AVC-кодера. Битрейт несжатого видеопотока легко определяется как произведение количества пикселов в каждом видеокадре (1920 x 1080) на количество битов, необходимых для представления каждого пиксела (8+2+2=12), и на количество кадров в секунду (30). В результате получаем около 750 Мбит/c. Из графиков видно, что в области среднего качества AVC-кодер обеспечивает битрейт порядка 10–12 Мбит/с. Таким образом, степень сжатия видеоинформации составляет порядка 60-75 раз. Как уже было сказано, для HEVC-кодера степень сжатия в 1.5 раза выше.
7 марта 2018
Читать другие статьи:
Глава 2. Межкадровое (Inter) предсказание в HEVC
Глава 3. Пространственное (Intra) предсказание в HEVC
Глава 4. Компенсация движения в HEVC
Глава 5. Постпроцессинг в HEVC
Глава 6. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 1
Глава 7. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 2
Глава 8. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 3
Глава 9. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 4
Глава 10. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 5
Автор
Олег Пономарев - 16 лет занимается вопросами видео кодирования и цифровой обработки сигналов, специалист в области распространения радиоволн, статистической радиофизики, доцент кафедры радиофизики НИ ТГУ, кандидат физико-математический наук. Руководитель исследовательской лаборатории Elecard.
Инструмент для детального анализа этапов кодирования видеопоследовательности - Elecard StreamEye
Инструмент для сравнения параметров видео, закодированного разными энкодерами