ГЛАВА 6

Арифметический кодер в классическом понимании, введение к бинарному арифметическому кодеру
Перечислим еще раз основные этапы обработки видеокадра при кодировании системой стандарта H.265/HEVC (рис.1). На первом этапе (с условным названием «Разбиение на блоки») кадр разбивается на блоки CU (Coding Unit). На следующем этапе изображение внутри каждого блока предсказывается с использованием пространственного (Intra) или временного (Inter) предсказания. При выполнении временного предсказания блок CU может быть разбит на подблоки PU (Prediction Unit), каждый из которых может иметь собственный вектор движения. Значения предсказанных отсчетов вычитаются из значений отсчетов кодируемого изображения. В результате для каждого блока CU формируется разностный двумерный сигнал Residual. На третьем этапе двумерный массив отсчетов разностного сигнала разбивается на блоки TU (Transform Unit), каждый из которых подвергается двумерному дискретному косинус-преобразованию Фурье (исключение здесь составляют блоки TU отсчетов яркости, полученных путем Intra-предсказания, размером 4x4, для которых используется дискретное синус-преобразование Фурье).
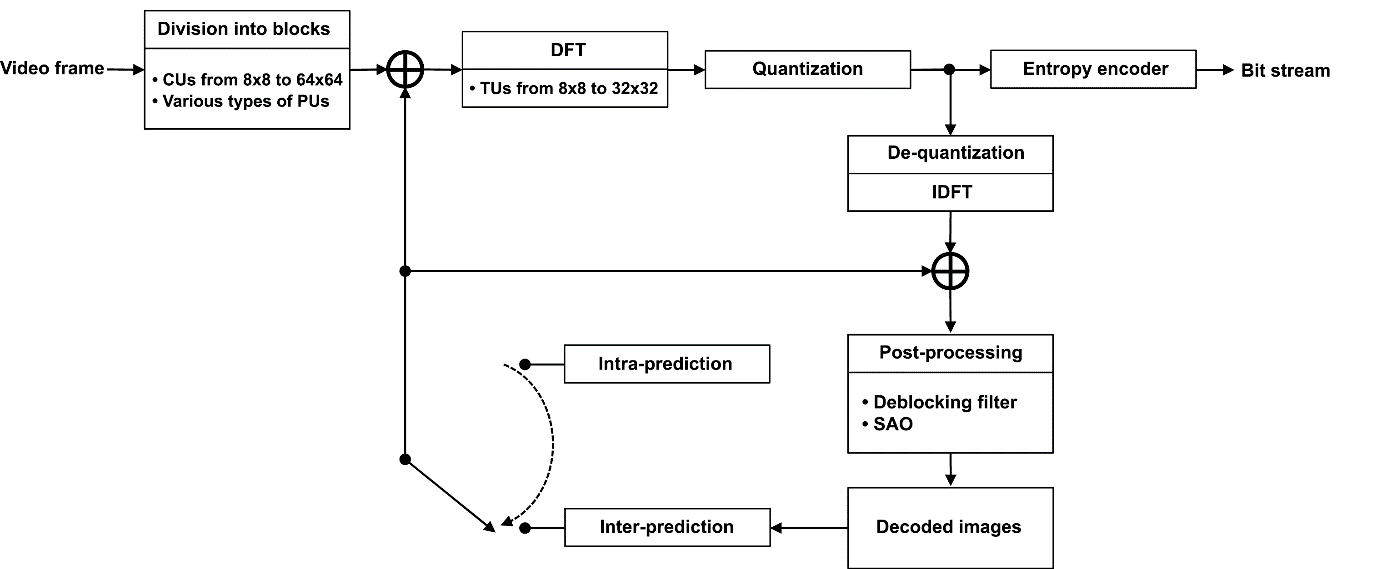
Рис 1. Основные этапы кодирования видеокадра в системе стандарта H.265/HEVC
На следующем этапе спектральные Фурье-коэффициенты разностного сигнала квантуются по уровню. Информация о всех произведенных на каждом из четырех этапах действиях, позволяющая восстановить закодированное изображение, поступает на вход энтропийного кодера. Это последний этап. Здесь поступающие данные подвергаются дополнительному беспотерьному сжатию по алгоритмам контекстно-адаптивного двоичного арифметического кодирования (Context Adaptive Binary Arithmetic Coding, сокращенно CABAC). Попробуем разобраться, что же означает эта последовательность из пяти слов.
Начнем со словосочетания «арифметическое кодирование». Чтобы проиллюстрировать идею арифметического кодирования рассмотрим простой пример. Попробуем сжать информационное сообщение, состоящее из 20 символов. Видов символов у нас будет всего три: символ «a», символ «b» и символ «EOF», который будет индицировать конец сообщения. Само сообщение будет следующим: {b, a, b, b, b, b, b, b, b, b, a, b, b, b, b, b, b, b, b, EOF}. Процедура сжатия будет заключаться в рекурсивном делении текущего интервала. Возьмем в качестве начального интервала [0, 1). Разобьем его на интервалы, длина которых будет пропорциональна частоте появления символов в сообщении. Символ «b» появляется в сообщении в 17 случаях из 20 возможных. Символ «a» – в 2 случаях из 20. Символ «EOF» появляется один раз. После разбиения будем иметь три интервала: [0, 2/20), [2/20, 19/20), [19/20, 1). Первый символ в сообщении – символ «b». В качестве текущего теперь выбираем отрезок, длина которого пропорциональна частоте появления символа «b». Т.е. текущим отрезком становится [2/20, 19/20). Повторяем процедуру разбиения текущего интервала, выбирая в качестве нового интервала тот, длина которого соответствует частоте появления в сообщении очередного символа. Процедуру повторяем до конца сообщения. Последовательность действий при нашем кодировании оформим в виде таблицы.
Таблица 1
Номер итера- ции | Текущий интервал | Результат разбиения | Символ в сообще- нии | ||
a | b | EOF | |||
1 | [0, 1) | [0, 0.1) | [0.1, 0.95) | [0.95, 1) | b |
2 | [0.1, 0.95) | [0.1, 0.185) | [0.185, 0.855) | [0.855, 0.95) | a |
3 | [0.1, 0.185) | [0.1, 0.1085) | [0.1085, 0.1808) | [0.1808, 0.185) | b |
4 | [0.1085, 0.1808) | [0.1085, | [0.1157, | [0.1771, | b |
5 | [0.1157, | [0.1157, | [0.1219, | [0.1741, | b |
6 | [0.1219, | [0.1219, | [0.1271, 0.1715) | [0.1715, | b |
7 | [0.1271, 0.1715) | [0.1271, | [0.1315, | [0.1692, | b |
8 | [0.1315, | [0.1315, 0.1353) | [0.1353, 0.1674) | [0.1674, | b |
9 | [0.1353, 0.1674) | [0.1353, | [0.1385, | [0.1657, | b |
10 | [0.1385, | [0.1385, | [0.1412, | [0.1644, | b |
11 | [0.1412, | [0.1412, | [0.1435, | [0.1562, | a |
12 | [0.1412, | [0.1412, | [0.1415, | [0.1434, | b |
13 | [0.1415, | [0.1415, | [0.1417, | [0.1433, 0.1434) | b |
14 | [0.1417, | [0.1417, | [0.1418, | [0.1432, | b |
15 | [0.1418, | [0.1418, | [0.1420, | [0.14317, | b |
16 | [0.1420, | [0.1420, | [0.1421, | [0.14311, | b |
17 | [0.1421, | [0.1421, | [0.1422, | [0.14306, | b |
18 | [0.1422, | [0.1422, | [0.1423, | [0.14302, 0.14306) | b |
19 | [0.1423, | [0.1423, | [0. 14235, | [0.14298, | b |
20 | [0. 14235, | [0.14235, | [0.14241, | [0.14295, | EOF |
Результатом рекурсивного деления текущего интервала стал выделенный жирным в таблице интервал, границы которого приведем без округления: [0.142948471255693, 0.142980027967343). В двоичной системе счисления полученный интервал представляется в виде [0.001 001 001 001 100 00100010101100001000011100111000000010, 0.001 001 001 001 101 00101011011010000000110011101010011101). Число 0.001 001 001 001 100 1 (в десятичной системе счисления это число 0.142959594726563), принадлежащее полученному интервалу, является результатом кодирования нашего сообщения. Это число содержит 16 бит. Таким образом, из сообщения длиной 20 символов мы получили 16-ти битовый код. Мы сжали наше сообщение!
Попробуем теперь его декодировать. Для этого опять возьмем исходный интервал [0, 1). Разделим его в соответствии с частотами появления символов в сообщении. Результат этого разбиения, очевидно, представлен в Таблице 1 в строке с номером итерации 1. Полученное число 0.142959594726563 принадлежит среднему интервалу [0.1, 0.95). Таким образом, первый декодированный символ – это символ «b» (что отражено в пятом столбце таблицы в первой строке). Текущим интервалом становится [0.1, 0.95). Опять делим его на три части в соответствии с частотами появления символов в сообщении. Результат разбиения показан во второй строке Таблицы 1. Число 0.142959594726563 принадлежит первому из интервалов, полученных при делении, [0.1, 0.185). Этот интервал имеет длину, пропорциональную частоте появления символа «a». Этот символ и является результатом декодирования на второй итерации. Из сказанного выше очевидно, что весь процесс декодирования уже отображен в Таблице 1. Итеративное деление текущего интервала при декодировании будет продолжаться до тех пор, пока не будет декодирован символ «EOF», сигнализирующий о конце сообщения.
Несмотря на то, что рассмотренные процедуры итеративного деления текущего отрезка действительно реализуют арифметическое кодирование и декодирование сообщения, они очень мало похожи на те действия, которые выполняются при кодировании/декодировании по алгоритмам CABAC. Прежде всего, это связано с двумя существенными, с точки зрения практического использования, недостатками рассмотренных процедур кодирования и декодирования. Во-первых, при кодировании мы получили результат только после того, как обработали все сообщение. До этого момента ни один бит результата нам не известен. Аналогично. Для начала процедуры декодирования нам необходимо знать весь набор битов, представляющий закодированное сообщение. Второй недостаток также достаточно очевиден из приведенного примера. При итеративном делении текущего отрезка на каждой итерации возрастает точность, необходимая для представления границ интервалов. Таким образом, чем длиннее сообщение, тем больший временной интервал (задержка) необходим в кодере и декодере для его обработки, тем выше точность (разрядность вычислений) требуется для реализации алгоритмов арифметического кодирования.
Отметим здесь несколько достаточно очевидных моментов, касающихся процедуры кодирования. Совершенно очевидно, что в том случае, когда текущий интервал полностью лежит в области от 0 до ½, текущий бит результата кодирования будет нулевым. Аналогично, в том случае, когда текущий интервал полностью лежит в области от ½ до 1, текущий бит результата кодирования будет единичным. В том же случае, когда левый конец текущего интервала меньше ½, а правый больше, но оба не отстоят от ½ более чем на ¼, значение текущего бита результата неизвестно. Однако, можно уверенно утверждать, что следующий бит результата будет иметь противоположное к текущему значение. После выдачи каждого текущего бита результата кодирования длину интервала можно удвоить. Все это позволило ввести процедуру удвоения длины текущего интервала, которая позволяет обойти оба указанных выше недостатка арифметического кодирования.
В стандарте эта процедура названа Ренормализацией. В процессе Ренормализации при кодировании (до окончания кодирования) сразу выдаются биты результата кодирования, а длина текущего интервала удваивается. Ренормализация выполняется итеративно после выбора каждого текущего интервала. Итерации продолжаются до тех пор, пока текущий интервал попадает полностью в один из трех интервалов: [0, 0.5), [0.25, 0.75), [0.5, 1). Если текущий интервал не лежит полностью ни в одном из этих трех интервалов, то итерации прекращаются. В противном случае, когда текущий интервал лежит в одном из этих трех, выполняется один из трех наборов действий. Т.е. каждый набор соответствует своему интервалу.
Если текущий интервал полностью принадлежит интервалу [0, 0.5), то выдается бит результата 0 и после него столько битов 1, сколько было накоплено на предыдущих символах. (Количество единиц, выдаваемых в результирующий битовый поток равно значению счетчика, называемого в стандарте bitsOutstanding. После вывода единичных битов счетчик сбрасывается в 0). Значения границ текущего интервала удваивается (В результате, естественно удваивается и длина интервала. Для краткости назовем это удвоение «расширением интервала вправо»).
Если текущий интервал полностью лежит внутри интервала [0.5, 1), то выдается бит результата 1 и после него столько битов 0, сколько было накоплено на предыдущих символах (Количество битов 0 опять равно значению счетчика bitsOutstanding. Счетчик сбрасывается в 0). Границы интервала смещаются влево так, чтобы расстояние от них до 1 удвоилось. (Назовем это удвоение «расширением интервала влево»).
Если текущий интервал полностью лежит внутри интервала [0.25, 0.75), то этот факт необходимо запомнить для последующей выдачи битов результата (увеличить на 1 значение счетчика bitsOutstanding). Левая граница текущего интервала смещается влево так, чтобы расстояние от нее до точки 0.5 удвоилось. Правая граница смещается вправо также с удвоением расстояния от нее до точки 0.5. (Назовем удвоение длины интервала в этом случае «расширением интервала в обе стороны»).
Кроме того, формализуем процедуру выбора последних двух бит закодированного сообщения, конкретизирующих выбор двоичного числа из полученного итеративным делением интервала. Эта процедура очень проста. Если левая граница полученного интервала меньше 0.25, то последними битами сообщения будет последовательность {0, 1}. В противном случае – это последовательность {1, 0}.
Проиллюстрируем работу процедуры ренормализации на примере кодирования того же 20-ти символьного сообщения {b, a, b, b, b, b, b, b, b, b, a, b, b, b, b, b, b, b, b, EOF}
Таблица 2
Номер итера- ции | Текущий интервал | Результат разбиения | Символ в сообще- нии | |||||
a | b | EOF | ||||||
1 | [0, 1) | [0, 0.1) | [0.1, 0.95) | [0.95, 1) | b | |||
2 | [0.1, 0.95) | [0.1, 0.185) | [0.185, 0.855) | [0.855, 1) | a | |||
[0.1, 0.185) | выдаем 0, расширяем интервал вправо | |||||||
[0.2, 0.37) | выдаем 0, расширяем интервал вправо | |||||||
[0.4, 0.74) | Увеличиваем счетчик, расширяем интервал в обе стороны | |||||||
3 | [0.3, 0.98) | [0.3, 0.368) | [0.368, 0.946) | [0.946, 0.98) | b | |||
4 | [0.368, 0.946) | [0.368,0.4258) | [0.4258, 0.9171) | [0.9171, 0.946) | b | |||
5 | [0.4258, 0.9171) | [0.4258, 0.4749) | [0.4749, 0.8925) | [0.8925, 0.9171) | b | |||
6 | [0.4749, 0.8925) | [0.4749, 0.5167) | [0.5167, 0.8717) | [0.8717, 0.8925) | b | |||
[0.5167, 0.8717) | выдаем 10, расширяем интервал влево, сбрасываем счетчик в 0 | |||||||
7 | [0.0334, 0.7433) | [0.0334, 0.1044) | [0.1044, 0.7078) | [0.7078, 0.7433) | b | |||
8 | [0.1044, 0.7078) | [0.1044, 0.1647) | [0.1647, 0.6776) | [0.6776, 0.7078) | b | |||
9 | [0.1647, 0.6776) | [0.1647, 0.2160) | [0.2160, 0.6520) | [0.6520, 0.6776) | b | |||
10 | [0.2160, 0.6520) | [0.2160, 0.2596) | [0.2596, 0.6302) | [0.6302, 0.6520) | b | |||
[0.2596, 0.6302) | Увеличиваем счетчик, расширяем интервал в обе стороны | |||||||
11 | [0.0192, 0.7604) | [0.0192, 0.0933) | [0.0933, 0.7233) | [0.7233, 0.7604) | a | |||
[0.0192, 0.0933) | выдаем 01, расширяем интервал вправо, сбрасываем счетчик | |||||||
[0.0384, 0.1867) | выдаем 0, расширяем интервал вправо | |||||||
[0.0769, 0.3733) | выдаем 0, расширяем интервал вправо | |||||||
12 | [0.1537, 0.7467) | [0.1537, 0.2130) | [0.2130, 0.7170) | [0.7170, 0.7467) | b | |||
13 | [0.2130, 0.7170) | [0.2130, 0.2634) | [0.2634, 0.6918) | [0.6918, 0.7170) | b | |||
[0.2634, 0.6918) | Увеличиваем счетчик, расширяем интервал в обе стороны | |||||||
14 | [0.0269, 0.8837) | [0.0269, 0.1125) | [0.1125, 0.8408) | [0.8408, 0.8837) | b | |||
15 | [0.1125, 0.8408) | [0.1125, 0.1854) | [0.1854, 0.8044) | [0.8044, 0.8408) | b | |||
16 | [0.1854, 0.8044) | [0.1854, 0.2473) | [0.2473, 0.7735) | [0.7735, 0.8044) | b | |||
17 | [0.2473, 0.7735) | [0.2473, 0.2999) | [0.2999, 0.7471) | [0.7471, 0.7735) | b | |||
[0.2999, 0.7471) | Увеличиваем счетчик, расширяем интервал в обе стороны | |||||||
18 | [0.0998, 0.9943) | [0.0998, 0.1892) | [0.1892, 0.9496 | [0.9496, 0.9943) | b | |||
19 | [0.1892, 0.9496) | [0.1892, 0.2653) | [0.2653, 0.9115) | [0.9115, 0.9496) | b | |||
20 | [0.2653, 0.9115) | [0.2653, 0.3299) | [0.3299, 0.8792) | [0.8792, 0.9115) | EOF | |||
[0.8792, 0.9115) | выдаем 100, расширяем интервал влево, сбрасываем счетчик в 0 | |||||||
[0.7585, 0.8231) | выдаем 1, расширяем интервал влево | |||||||
[0.5169, 0.6462) | выдаем 1, расширяем интервал влево | |||||||
[0.0339, 0.2924) | выдаем 0, расширяем интервал вправо | |||||||
[0.0678, 0.5848 | т.к. 0.0678<0.25, выдаем 01 | |||||||
В результате кодирования получили 001 001 001 001 100 1. Т.е. те же 16 бит, которые мы получали и без использования процедуры Ренормализации.
Отметим еще один момент. Процедуру итеративного деления текущего интервала на части, длины которых пропорциональны частотам появления символов в сообщении легко формализовать. Действительно, если обозначить за  относительную частоту i-го символа (в нашем примере у первого символа «a» эта частота равна 0.1), за
относительную частоту i-го символа (в нашем примере у первого символа «a» эта частота равна 0.1), за  ,
,  , то границы текущего интервала на каждой итерации могут быть рассчитаны как:
, то границы текущего интервала на каждой итерации могут быть рассчитаны как:
R = Hc - Lc
L = Lc + P1 ∙ R ,
H = Lc + P2 ∙ R ,
где Lc – левая граница текущего интервала, L – новое значение левой границы текущего интервала после деления, Hc– правая граница текущего интервала, H – новое значение правой границы текущего интервала после деления.
13 мая 2019
Читать другие статьи:
Глава 1. Просто о видеокодировании
Глава 2. Межкадровое (Inter) предсказание в HEVC
Глава 3. Пространственное (Intra) предсказание в HEVC
Глава 4. Компенсация движения в HEVC
Глава 5. Постпроцессинг в HEVC
Глава 7. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 2
Глава 8. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 3
Глава 9. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 4
Глава 10. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 5
Автор:
Олег Пономарев - 16 лет занимается вопросами видео кодирования и цифровой обработки сигналов, специалист в области распространения радиоволн, статистической радиофизики, доцент кафедры радиофизики НИ ТГУ, кандидат физико-математический наук. Руководитель исследовательской лаборатории Elecard.
Инструмент для детального анализа этапов кодирования видеопоследовательности - Elecard StreamEye
Инструмент для сравнения параметров видео, закодированного разными энкодерами