Векторные вычисления — такие компьютерные вычисления, когда при выполнении одной инструкции процессора производится не одна операция, а одновременно несколько однотипных операций над несколькими порциями данных. Иначе этот принцип называется SIMD — от английского Single Instruction, Multiple Data. Название возникло из очевидной аналогии с векторной алгеброй: операции между векторами обозначаются одним символом, но подразумевают, что одновременно выполняются несколько арифметических действий над компонентами вектора.
Изначально векторные вычисления выполнялись специализированными сопроцессорами, которые являлись основной частью суперкомпьютеров. В 1990-е годы в некоторых процессорах архитектуры x86 и нескольких других появились векторные расширения: специальные регистры с повышенной разрядностью и специальные векторные инструкции, оперирующие этими регистрами.
Векторные инструкции применяются там, где требуется выполнение множества однотипных операций и высокая производительность вычислений. Это всевозможные задачи вычислительной математики и математического моделирования, компьютерная графика и компьютерные игры. Без векторных вычислений сегодня невозможно достичь такой производительности вычислительной системы, которая требуется для обработки видеосигналов и, в особенности, кодирования и декодирования видео. Необходимо отметить, что для некоторых задач и алгоритмов векторные инструкции не увеличивают производительность.
В этой статье мы привели примеры использования векторных инструкций и реализации нескольких алгоритмов и функций с их помощью. Примеры в основном взяты из области обработки изображений и сигналов, но они могут оказаться полезными и программистам, работающими над задачами в других областях. Векторные инструкции помогают увеличить производительность, хотя и не гарантируют этого: от программиста требуется не только внимательность и аккуратность, но нередко и изобретательность, чтобы в полной мере использовать возможности, предоставляемые компьютером.
Инструкции и регистры
Векторные вычисления — такие вычисления, когда при выполнении одной инструкции процессора производится одновременно несколько однотипных операций. Этот принцип в настоящее время реализован не только в специализированных процессорах, но и в процессорах архитектуры x86 и ARM в виде векторных расширений. Эти расширения представляют собой специальные векторные регистры с повышенной относительно регистров общего назначения разрядностью. Для работы с этими регистрами имеются специальные векторные инструкции, которые дополняют систему инструкций процессора.
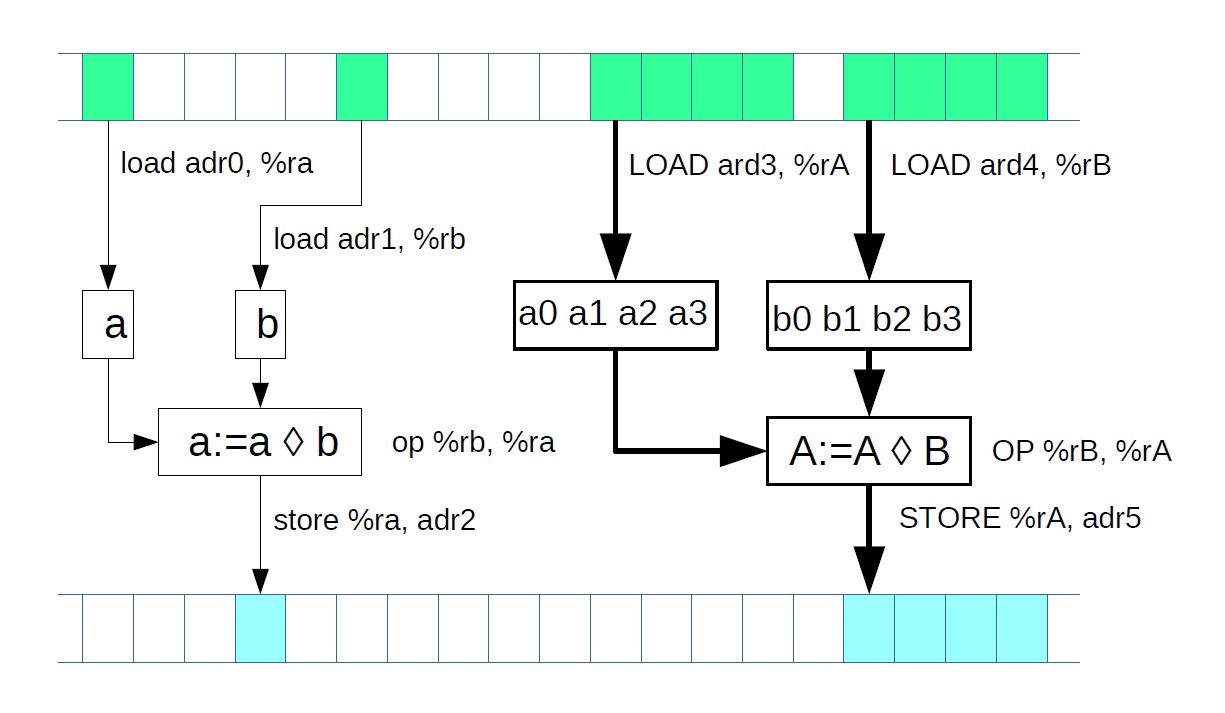
Рис.1 Скалярные и векторные вычисления
Как правило, векторные инструкции реализуют те же операции, что и скалярные (обычные) инструкции (см. рис. 1), но благодаря большому объёму обрабатываемых данных производительность этих инструкций выше. Если для регистра общего назначения при выполнении некоторой инструкции предполагается, что в нём находится только одна порция данных определённого типа (целое число определённой разрядности, число с плавающей запятой), то в векторном регистре одновременно находится столько независимых порций данных определённого типа, сколько позволяет разместить ёмкость регистра. И такое же количество одновременных независимых операций может быть произведено над этими данными при выполнении векторной инструкции — и во столько же раз повышается производительность вычислений. Повысить производительность процессора, выполняя несколько одинаковых операций одновременно, — основная задача векторных расширений.
В процессорах архитектуры x86 первым векторным расширением был набор инструкций MMX, оперирующих восемью 64-битными регистрами MM0-MM7. MMX сменили более производительные 128-битные инструкции SSE (инструкции для работ числами с плавающей запятой) и SSE2 (целочисленные инструкции и инструкции для работ с числами с плавающей запятой двойной точности), оперирующие регистрами xmm0-xmm7. Позже появились наборы 128-битных инструкций SSE3, SSSE3, SSE4.1 и SSE4.2, которые дополнили SSE и SSE2 несколькими полезными инструкциями. Большинство инструкций из перечисленных наборов используют два регистра-операнда, результат записывается в один из этих регистров, а его первоначальное содержимое теряется.
Следующий шаг в развитии векторных расширений — ещё более производительные 256-битные инструкции AVX и AVX2, которые оперируют 256-битными регистрами ymm0-ymm15. Кроме того, эти инструкции используют три регистра-операнда: исходные данные содержатся в двух регистрах, результат операции записывается в третий регистр, а содержимое двух других регистров остаётся неизменным. Новейший на сегодняшний день набор векторных инструкций — AVX-512, который оперирует 32 512-битными регистрами zmm0-zmm31. AVX-512 используется в некоторых серверных процессорах для высокопроизводительных вычислений.
С массовым появлением 64-битных процессоров инструкции MMX признаны устаревшими. Инструкции SSE и SSE2 с появлением AVX и AVX2 не вышли из употребления и продолжают активно использоваться. В процессорах x86 сохраняется обратная совместимость: если процессором поддерживается AVX2, то им поддерживаются и SSE/SSE2, а также SSE3, SSSE3, SSE4.1 и SSE4.2. Аналогично, процессор с поддержкой, например, SSSE3, поддерживает и все более ранние наборы инструкций.
Для процессорной архитектуры ARM разработано векторное расширение NEON. Разрядность векторных инструкций — 64 и 128 бит, которые оперируют тридцатью двумя 64-битными регистрами либо шестнадцатью 128-битными (в ARM64 имеется 32 128-битных регистров).
Поскольку векторные инструкции привязаны к конкретной процессорной архитектуре (а нередко — и к конкретному процессору), то программы, использующие их, становятся непереносимыми. Следовательно, для достижения переносимости необходимо делать несколько реализаций одного и того же алгоритма с использованием разных наборов инструкций.
Интринсики
Каким образом программист может использовать векторные инструкции? Прежде всего, их можно использовать в ассемблерном коде.
Можно получить доступ к векторным инструкциям и в программе на языке высокого уровня (в частности, C/C++) без ассемблерных вставок. Для этого используются так называемые интринсики (intrinsics) — встроенные объекты компилятора. В заголовочном файле объявлен один или несколько типов данных (с точки зрения программиста, это массив фиксированной длины, но без возможности доступа к элементам этого массива), переменной одного из этих типов соответствует векторный регистр. Также в заголовочном объявлены функции, которые принимают аргументы, возвращают значения указанных выше типов и производят с точки зрения программиста те же операции над данными, что и соответствующие им векторные инструкции. В действительности же настоящей программной реализации этих функций не существует: компилятор при генерации объектного кода заменяет вызов функции векторной инструкцией. Таким образом, с помощью интринсиков можно написать программу на языке высокого уровня, близкую или равную по производительности программе, написанной на языке ассемблера.
Для доступа к интринсикам достаточно подключить соответствующий заголовочный файл. Интринсики не являются частью стандартов языков C/C++, но поддерживаются основными компиляторами: GCC, Clang, MSVC, Intel.
Интринсики позволяют также упорядочить работу с разнообразными типами обрабатываемых данных. Важно отметить, что процессору (по крайней мере, в архитектуре x86) недоступна информация о типе данных, содержащихся в регистре. При выполнении той или иной векторной инструкции они интерпретируются как данные определённого, связанного с инструкцией типа: числа с плавающей запятой, целого числа некоторой разрядности со знаком или без знака. Контролировать корректность производимых вычислений при этом должен программист, что требует немалого внимания. Тем более, иногда тип данных может изменяться: например, при целочисленном умножении разрядность произведения равна сумме разрядностей множителей. Интринсики позволяют в некоторой степени упростить задачу.
Так, векторным регистрам xmm (SSE) соответствуют три типа данных [1]:
__m128, «массив» из четырёх чисел с плавающей запятой с одинарной точностью;
__m128d, «массив» из двух чисел с плавающей запятой двойной точности;
__m128i, 128-битный регистр, который можно рассматривать как «массив» 8-, 16-,32- и 64-битных чисел. Поскольку конкретная векторная инструкция работает, как правило, с одним из трёх типов данных (число с плавающей запятой одинарной точности, двойной точности, целочисленный), то и аргументы функций-векторных инструкций имеют один из трёх указанных типов. Подобным образом устроена и система типов AVX2: в ней имеются типы __m256 (с плавающей запятой), __m256d (двойной точности) и __m256i (целочисленный).
Интринсики NEON реализуют ещё более развитую систему типов [2]. 128-битному регистру соответствуют типы int32x4_t, int16x8_t, int8x16_t, float32x4_t, float64x2_t. В NEON имеются и типы данных, содержащие несколько регистров, например int8x16x2_t. В подобной системе в любой момент известны конкретный тип и разрядность содержимого регистра, и меньше вероятность допустить ошибку там, где преобразуется тип данных и меняется их разрядность.
Приведём пример простой функции, реализованной с помощью набора инструкций SSE2.
// 1.2.1: Example of SSE2 intrinsics
// for int32_t
#include <stdint.h>
// for SSE2 intrinsics
#include <emmintrin.h>
void bar(void)
{
int32_t array_a[4] = {0,2,1,2}; // 128 bit
int32_t array_b[4] = {8,5,0,6};
int32_t array_c[4];
__m128i a,b,c;
a = _mm_loadu_si128((__m128i*)array_a); // loading array_a into register a
b = _mm_loadu_si128((__m128i*)array_b);
c = _mm_add_epi32(a, b); // must be { 8,7,1,8 }
_mm_storeu_si128((__m128i*)array_c, c);
}
В этом примере содержимое массива array_a загружается в один векторный регистр, а массива array_b — в другой. Затем соответствующие 32-битные элементы регистров складываются, и результат записывается в третий регистр, а затем копируется в массив array_c. В этом примере можно отметить ещё одну особенность интринсиков: _mm_add_epi32 принимает два аргумента-регистра и возвращает одно значение-регистр. Но в действительности инструкция paddd, которой соответствует _mm_add_epi32, имеет только два регистра-операнда, в один из которых записывается результат операции с потерей первоначального содержимого регистра. Чтобы сохранить содержимое регистров при компиляции c = _mm_add_epi32(a, b), компилятор добавляет дополнительные операции копирования из регистра в регистр.
Имена интринсиков выбраны так, чтобы облегчить чтение исходного текста программ. В архитектуре x86 имя состоит из трёх частей: префикса, обозначений операции и типа скалярных данных (рисунок 2, а.). Префикс обозначает разрядность векторного регистра: _mm_ для 128 бит, _mm256_ для 256 бит и _mm512_ для 512 бит соответственно. Обозначения некоторых типов данных приведены в таблице 1. Подобным образом выбраны имена интринсиков и в наборе ARM NEON (рисунок 2, б.). Имеется, напомним, два типа векторных регистров (64 и 128-битные), и буква q обозначает, что инструкция специализируется на 128-битных регистрах.
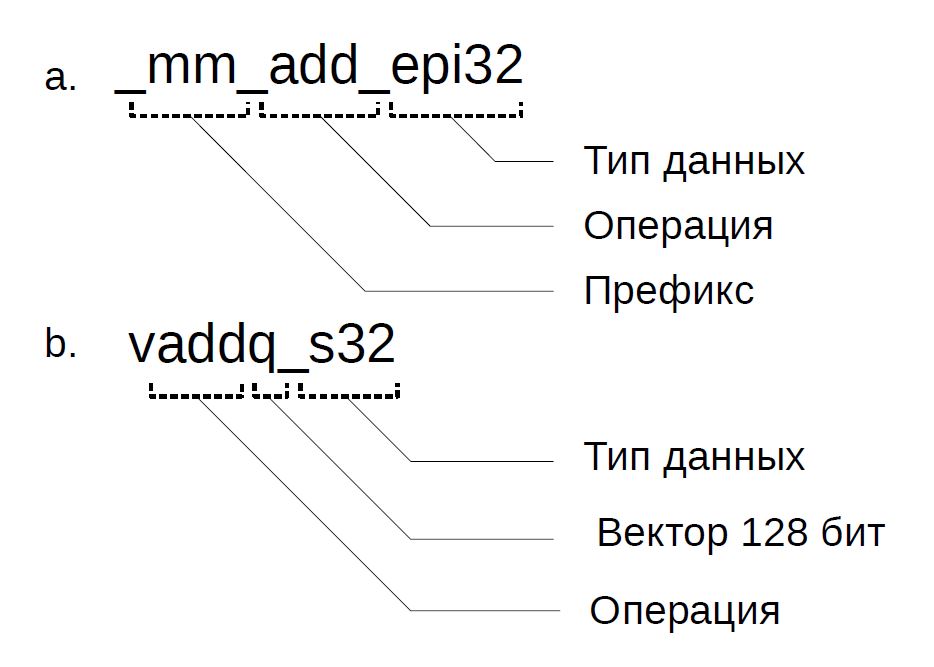
Рис.2 Имена интринсиков в SSE2 (а) и ARM NEON (b)
Таблица 1: Обозначение типов данных интринсиков архитектуры х86 (b)
| Обозначение | Описание |
| ps | Число с плавающей запятой одинарной точности |
| pd | Число с плавающей запятой двойной точности |
| epi8 | Целое число, 8 бит, со знаком |
| epu8 | Целое число, 8 бит, без знака |
| epi16 | Целое число, 16 бит, со знаком |
| epi32 | Целое число, 32 бит, со знаком |
| epi64 | Целое число, 64 бит, со знаком |
| si128 | Целое число, 128 бит |
| si256 | Целое число, 256 бит |
Имена типов данных (__m128i и другие) и имена функций-интринсиков фактически стали стандартными в разных компиляторах. Далее в статье векторные инструкции будут именоваться не мнемокодом, а соответствующим им именем интринсика.
Важнейшие векторные инструкции
В этом разделе рассказывается о важнейших классах инструкций. Приведены примеры часто употребляемых и полезных инструкций в основном из архитектуры x86, но уделено внимание и инструкциям ARM NEON.
Обмен данными с оперативной памятью
Чтобы процессор произвел какие-либо действия с данными, которые находятся в оперативной памяти, необходимо сначала загрузить эти данные в регистр процессора. А после завершения обработки данные необходимо записать обратно в оперативную память.
Большинство векторных инструкций работает в формате «регистр — регистр», то есть операндами инструкций являются векторные регистры, и в них же записывается результат работы инструкций. Для обмена данными с оперативной памятью есть ряд специализированных инструкций.
Инструкция _mm_loadu_si128(__m128i* addr) извлекает из оперативной памяти непрерывный массив целочисленных данных длиной 128 бит с начальным адресом addr и записывает в выбранный векторный регистр. В противоположность ей, инструкция _mm_storeu_si128(__m128i* addr, __m128i a) копирует в оперативную память, начиная с адреса addr, непрерывный массив данных длиной 128 бит, которые содержатся в регистре a. При использовании этих инструкций адрес addr может быть произвольным (естественно, при чтении и записи не должен происходить выход за пределы массива). Инструкции _mm_load_si128 и _mm_store_si128 аналогичны приведённым выше и потенциально более производительны. Но они требуют, чтобы addr был кратен 16 байтам (иначе говоря, выровнен по границе 16 байт), иначе при их выполнении произойдёт аппаратное исключение.
Для загрузки и записи данных с плавающей запятой одинарной и двойной точности (длиной 128 бит) существуют специализированные инструкции _mm_loadu_ps и _mm_storeu_ps и, соответственно, _mm_loadu_pd и _mm_storeu_pd.
Нередко возникает необходимость загрузить данные в меньшем количестве, чем вмещает векторный регистр. Инструкция _mm_loadl_epi64(__m128i* addr) извлекает из оперативной памяти непрерывный массив данных длиной 64 бит, начиная с адреса addr и записывает их в младшую половину выбранного векторного регистра, биты же старшей половины регистра устанавливает нулевыми. Инструкция _mm_storel_epi64(__m128i* addr, __m128i a), обратная ей, записывает в оперативную память младшие 64 бита регистра addr.
Инструкция _mm_cvtsi32_si128(int32_t a) копирует 32 бита целочисленной переменной в младшие 32 бита векторного регистра, остальные биты регистра устанавливаются нулевыми. Напротив, _mm_cvtsi128_si32(__m128i a) копирует младшие 32 бита регистра в целочисленную переменную.
Логические операции и операции сравнения
В наборе SSE2 представлены инструкции, выполняющие следующие логические операции: «И», «ИЛИ», «исключающее ИЛИ», «И-НЕ». Имена инструкций, соответственно, следующие: _mm_and_si128, _mm_or_si128, _mm_xor_si128 и _mm_andnot_si128. Инструкции полностью аналогичны побитовым операциям, выполняемым над целыми числами, только разрядность числа равна не 32 или 64, а 128 битам.
Часто используемая инструкция _mm_setzero_si128(), которая устанавливает все биты регистра-приёмника нулевыми, реализована при помощи операции «исключающее ИЛИ», у которой оба операнда — один и тот же регистр.
С логическими инструкциями тесно связаны инструкции сравнения. Эти инструкции сопоставляют друг другу соответствующие элементы двух регистров-источников и проверяют выполнение некоторого условия (равенство либо неравенство). Если условие выполняется, то они устанавливают все биты элемента в регистре-приёмнике равными 1, в противном случае все биты устанавливаются равными 0. Например, инструкция _mm_cmpeq_epi32(__m128i a, __m128i b) проверяет 32-битные элементы регистров a и b на равенство. Результаты проверки нескольких разных условий можно объединить при помощи логических инструкций.
Арифметические операции и сдвиги
Инструкции, принадлежащие этой группе, несомненно, самые востребованные.
Для вычислений с плавающей точкой и в x86, и в ARM есть инструкции, которые реализуют все четыре арифметические операции и вычисляют квадратный корень для чисел однократной и двойной точности. В х86 для чисел однократной точности эти инструкции следующие: _mm_add_ps, _mm_sub_ps, _mm_mul_ps, _mm_div_ps и _mm_srqt_ps.
Приведём простой пример использования арифметических инструкций с плавающей запятой. Здесь, аналогично примеру в разделе 2 суммируются элементы двух массивов src0 и src1, а результат записывается в массив dst. При этом количество элементов, которые необходимо просуммировать, задано параметром len. В том случае, если len не кратно количеству элементов, которые вмещает векторный регистр (в нашем случае это будет четыре и два), часть элементов обрабатывается обычным способом, без векторизации.
// 1.3.1 Sum of elements of two arrays
/* necessary for SSE and SSE2 */
#include <emmintrin.h>
#include <emmintrin.h>
void sum_float( float src0[], float src1[], float dst[], size_t len)
{
__m128 x0, x1; // floating-point, single precision
size_t len4 = len & ~0x03;
for(size_t i = 0; i < len4; i+=4)
{
x0 = _mm_loadu_ps(src0 + i); // loading of four float values
x1 = _mm_loadu_ps(src1 + i);
{
__m128 x0, x1; // floating-point, single precision
size_t len4 = len & ~0x03;
for(size_t i = 0; i < len4; i+=4)
{
x0 = _mm_loadu_ps(src0 + i); // loading of four float values
x1 = _mm_loadu_ps(src1 + i);
x0 = _mm_add_ps(x0,x1);
_mm_storeu_ps(dst + i, x0);
}
for(size_t i = len4; i < len; i++)
{
dst[i] = src0[i] + src1[i];
}
}
}
for(size_t i = len4; i < len; i++)
{
dst[i] = src0[i] + src1[i];
}
}
void sum_double( double src0[], double src1[], double dst[], sizе_t len)
{
__m128d x0, x1; // floating-point, double precision
size_t len2 = len & ~0x01;
for(size_t i = 0; i < len2; i+=2)
{
x0 = _mm_loadu_pd(src0 + i ); //loading of two double values
x1 = _mm_loadu_pd(src1 + i );
{
__m128d x0, x1; // floating-point, double precision
size_t len2 = len & ~0x01;
for(size_t i = 0; i < len2; i+=2)
{
x0 = _mm_loadu_pd(src0 + i ); //loading of two double values
x1 = _mm_loadu_pd(src1 + i );
x0 = _mm_add_pd(x0,x1);
_mm_storeu_pd(dst + i, x0);
}
if(len2 != len)
{
dst[len2] = src0[len2] + src1[len2];
}
}
}
if(len2 != len)
{
dst[len2] = src0[len2] + src1[len2];
}
}
Для работы с целочисленными данными некоторой арифметической операции, как правило, есть несколько однотипных инструкций, каждая из которых специализируется на данных определённой разрядности. Например, операции сложения и вычитания. Для 16-битных целых чисел со знаком есть инструкции _mm_add_epi16 и _mm_sub_epi16 (выполняющие сложение и, соответственно, вычитание). Аналогичные им инструкции имеются и для разрядности 8, 32 и 64 бит. То же касается и логического сдвига влево и вправо, который реализован для разрядности 16, 32 и 64 бит (для 16 бит инструкции _mm_slli_epi16 и _mm_srli_epi16 соответственно). Арифметический же сдвиг вправо реализован только для разрядности 16 и 32 бит: это инструкции _mm_srai_epi16 и _mm_srai_epi32. ARM NEON также предоставляет инструкции для этих операций: для разрядностей 8, 16, 32 и 64 бит как для чисел со знаком, так и без знака.
Инструкции _mm_slli_si128(__m128i a, int imm) и _mm_srli_si128(__m128i a, int imm) интерпретируют содержимое регистра как 128-битное число, которое сдвигают на imm байт (не бит!) влево и, соответственно, вправо.
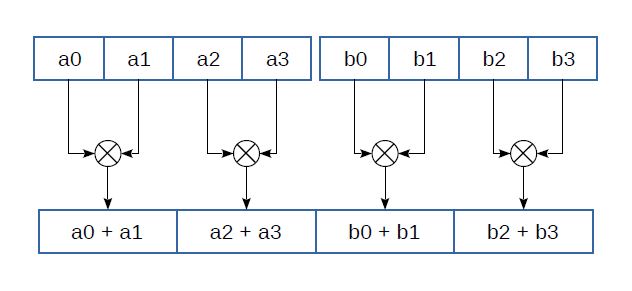
Рис.3 Горизонтальное сложение
В наборах инструкций SSE3 и SSSE3 появляются инструкции для горизонтального сложения (рисунок 3): _mm_hadd_ps(__m128 a, __m128 b), _mm_hadd_pd(__m128d a, __m128d b), _mm_hadd_epi16(__m128i a, __m128i b) и _mm_hadd_epi32(__m128i a, __m128i b). При горизонтальном сложении складываются соседние элементы одного и того же регистра. Добавлены инструкции и для горизонтального вычитания (_mm_hsub_ps и другие), которые таким же образом производят вычитание. Похожие инструкции, реализующие парное сложение (например, vpaddq_s16(int16x8_t a, int16x8_t b)), есть среди инструкций ARM NEON.
При целочисленном умножении разрядность произведения в общем случае равна сумме разрядностей сомножителей. Тогда, если умножить, например, 16-битные элементы одного регистра на соответствующие элементы другого, то в общем случае результаты произведений получаются 32-битные, и для их размещения потребуется два регистра, а не один.
Инструкция _mm_mullo_epi16(__m128i a, __m128i b) производит умножение 16-битных элементов регистров a и b, и записывает в регистр-приёмник младшие 16 бит 32-битного произведения. Напротив, _mm_mulhi_epi16(__m128i a, __m128i b) записывает в регистр-приёмник старшие 16 бит произведения. Результаты работы этих инструкций можно объединить и получить 32-битные произведения, если воспользоваться инструкциями _mm_unpacklo_epi16 и _mm_unpackhi_epi16, о которых речь пойдёт далее. Разумеется, если сомножители достаточно малы, то достаточно и одной _mm_mullo_epi16.
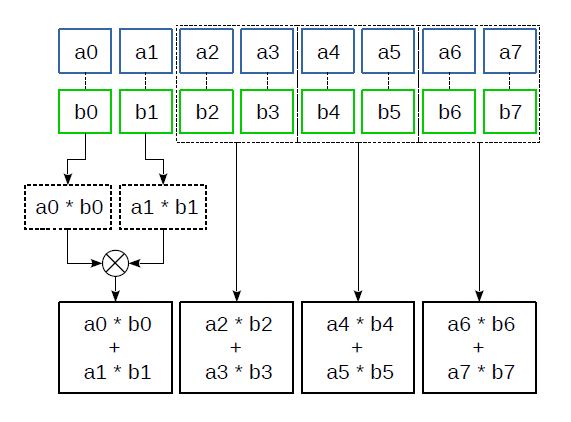
Рис.4 Инструкция _mm_madd_epi16
Инструкция _mm_madd_epi16(__m128i a, __m128i b) производит умножение 16-битных элементов регистров a и b, а затем складывает получившиеся соседние 32-битные произведения (рисунок 4). Эта инструкция оказывается особенно полезной при реализации всевозможных фильтров, дискретно-косинусных и других преобразований, где требуется много умножений совместно со сложениями: произведения сразу преобразуются в удобный 32-битный формат, а количество необходимых операций сложения сокращается.
Инструкции умножения ARM NEON весьма разнообразны. Имеются инструкции с увеличением разрядности произведения (например, vmull_s16) и без него; инструкции, которые умножают вектор на скаляр (например, vmul_n_f32). Инструкции, подобной _mm_madd_epi16, в наборе NEON нет, зато есть инструкции, выполняющие умножение с накоплением, которое выражается формулой: $\displaystyle a_{i} =a_{i} +( b_{i} c_{i}) ,\ i=1..n $ . Подобные инструкции имеются и для архитектуры x86 (набор инструкций FMA), но только для чисел с плавающей запятой.
Что касается векторного целочисленного деления, то оно не реализовано ни в архитектуре x86, ни в ARM.
Перестановка и перемешивание
Для группы инструкций, о которых далее пойдёт речь, не существует аналогичных скалярных инструкций процессора. При их выполнении не образуются новые значения: либо производится перестановка данных внутри регистра, либо данные, взятые из нескольких регистров-источников, записываются в определённом порядке в регистр-приёмник. На первый взгляд, эти инструкции мало полезны, но в действительности их значение очень велико. Без них многие алгоритмы невозможно реализовать эффективно.
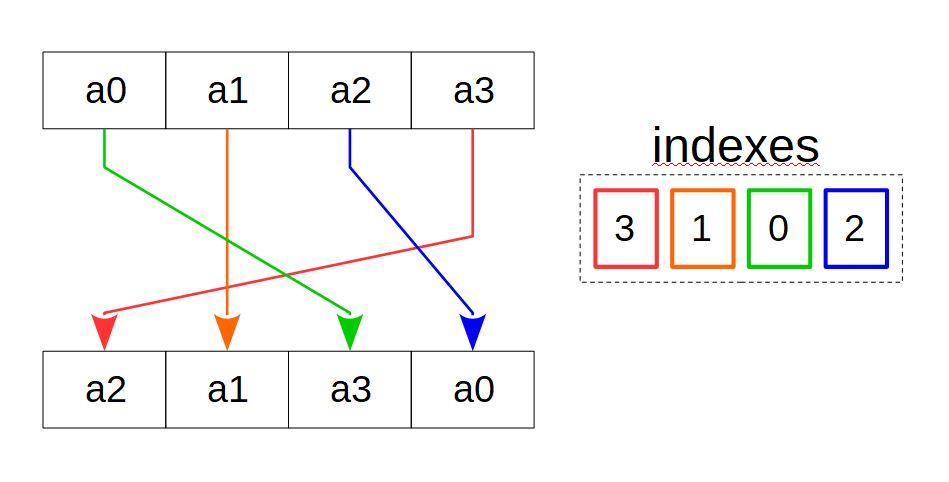
Рис.5 Копирование по шаблону
Несколько векторных инструкций в x86 и ARM реализуют копирование по шаблону (рисунок 5). Пусть имеются массив-источник, массив-приёмник, а также массив индексов, количество элементов в котором равно количеству элементов массива-приёмника, и при этом каждый элемент массива индексов соответствует элементу массива-приёмника. Значение элемента массива индексов указывает на тот элемент массива-источника, который нужно скопировать в соответствующий элемент массива-приёмника. Задавая различные индексы, можно осуществить всевозможные перестановки элементов, их дублирование.
В векторных инструкциях в качестве массива-источника и массива приёмника выступают векторные регистры или их группы. В качестве массива индексов может выступать также векторный регистр или же целочисленная константа, группы битов которой соответствуют элементам регистра-приёмника и кодируют элементы источника.
Одна из инструкций, реализующих принцип копирования по шаблону, — инструкция SSE2 _mm_shuffle_epi32(__m128i a, const int im), которая копирует выбранные 32-битные элементы регистра-источника в регистр-приёмник. В качестве массива индексов выступает второй операнд-целочисленная константа, значение которой задаёт шаблон копирования. Инструкция обычно используется совместно со стандартным макросом _MM_SHUFFLE, который делает задание шаблона копирования более наглядным. Например, при выполнении
a = _mm_shuffle_epi32(b,_MM_SHUFFLE(0,1,2,3));
32-битные элементы b записываются в регистр a в обратном порядке. А при выполнении
a = _mm_shuffle_epi32(b,_MM_SHUFFLE(2,2,2,2));
значения всех элементов регистра a становятся равными одному и тому же значению, а именно значению третьего элемента регистра b.
Инструкции _mm_shufflelo_epi16 и _mm_shufflehi_epi16 работают аналогично, но копируют выбранные 16-битные элементы из младшей и, соответственно, старшей половины регистра, а оставшуюся половину регистра копируют в регистр-приёмник без изменений. Покажем для примера, как с помощью этих инструкций и _mm_shuffle_epi32 можно переставить в обратном порядке 16-битные элементы 128-битного регистра всего за три операции. Вот как это делается:
// a: a0 a1 a2 a3 a4 a5 a6 a7
a = _mm_shuffle_epi32(a, _MM_SHUFFLE(1,0,3,2)); // a4 a5 a6 a7 a0 a1 a2 a3
a = _mm_shufflelo_epi16(a, _MM_SHUFFLE(0,1,2,3)); // a7 a6 a5 a4 a0 a1 a2 a3
a = _mm_shufflehi_epi16(a, _MM_SHUFFLE(0,1,2,3)); // a7 a6 a5 a4 a3 a2 a1 a0
Сначала меняются местами старшая и младшая половины регистра, а затем 16-битные элементы каждой из половин переставляются в обратном порядке.
Инструкция _mm_shuffle_epi8(__m128i a, __m128i i) из набора SSSE3 тоже осуществляет копирование по шаблону (правда, регистр-источник и регистр-приёмник у этой инструкции совпадают, так что это скорее «перестановка по шаблону»), но работает с байтами. Индексы задаются значениями байтов второго операнда — регистра. Эта инструкция позволяет осуществить гораздо более разнообразные перестановки данных, чем описанные выше инструкции, и благодаря этому во многих случаях возможно упростить и ускорить вычисления. Так, действие, показанное в примере выше, можно осуществить единственной инструкцией:
a = _mm_shuffle_epi8(a, i);
Для этого значения байта i должны быть следующими (начиная с младшего байта): 4,15,12,13,10,11,8,9,6,7,4,5,2,3,0,1
В наборе ARM NEON копирование по шаблону реализуют несколько инструкций, которые работают с одним регистром-источником (например, vtbl1_s8 (int8x8_t a, int8x8_t idx)) либо с группой регистров (например, vtbl4_u8(uint8x8x4_t a, uint8x8_t idx)). Инструкция vqtbl1q_u8(uint8x16_t t, uint8x16_t idx) аналогична _mm_shuffle_epi8.
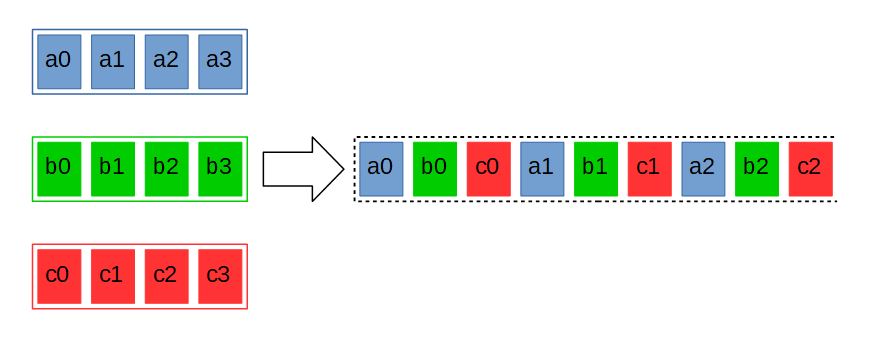
Рис.6 Перемешивание
Другая операция, реализуемая векторными инструкциями — перемешивание. Пусть имеется массив $\displaystyle A $ с элементами $\displaystyle a_{0} ,a_{1} ,...,a_{n} $, массив $\displaystyle B $, с элементами $\displaystyle b_{0} ,b_{1} ,...,b_{n} $, … массив $\displaystyle Z $ с элементами $\displaystyle z_{0} ,z_{1} ,...,z_{n} $. При выполнении этой операции элементы этих массивов объединяются в один в следующем порядке : $\displaystyle a_{0} ,b_{0} ...,z_{0} ,a_{1} ,b_{1} ,...,z_{1} ,...,a_{n} ,b_{n} ,...,z_{n}$ (рисунок 6). В векторных инструкциях и в этом случае в качестве исходных массивов выступают регистры-источники, и притом только два. Очевидно, что при выполнении этой операции объём данных остаётся постоянным, а значит, и регистров-приёмников тоже должно быть два.
В векторных инструкциях x68 регистр-приёмник может быть только один, поэтому инструкции, реализующие перемешивание, обрабатывают только половину входных данных. Так, инструкция _mm_unpacklo_epi16(__m128i a, __m128i b) перемешивает 16-битные элементы младших половин регистров a и b, а дополняющая её инструкция _mm_unpackhi_epi16(__m128i a, __m128i b) — старших. Таким же образом работают инструкции для разрядностей 8, 32 и 64 бита. Инструкции _mm_unpacklo_epi64 и _mm_unpackhi_epi64, по сути, просто объединяют младшие и, соответственно, старшие 64 бита двух регистров. Парные инструкции нередко используются совместно.
Аналогичные инструкции есть и среди инструкций ARM NEON (семейство инструкций vzip). Некоторые из инструкций используют не один, а два регистра-приёмника и, таким образом, обрабатывают входные данные полностью. Имеются и такие инструкции, которые производят обратную операцию (vuzp), и для которых нет аналогов среди инструкций x86.
Инструкция _mm_alignr_epi8(__m128i a, _m128i b, int imm) копирует в регистр-приёмник байты регистра-источника b, начиная с выбранного байта imm, а оставшиеся байты копирует из регистра a, начиная с младшего байта. Пусть байты регистра a имеют значения a0..a15, а байты регистра b — значения b0..b15. Тогда при выполнении
a = _mm_alignr_epi8(a, b, 5);
в регистр a будут записаны следующие байты: b5, b6, b7, b8, b9, b10, b11, b12, b13, b14, b15, a0, a1, a2, a3, a4. Подобные инструкции, которые работают не с байтами, а с элементами определённой разрядности, предоставляет ARM NEON [3].
Инструкции AVX и AXV2
Дальнейшее развитие векторных инструкций архитектуры x86 связано с появлением 256-битных инструкций AVX и AVX2. Что эти инструкции предоставляют разработчикам?
Прежде всего, вместо 8 (16) 128-битных регистров XMM имеется 16 256-битных регистров YMM0 – YMM15, младшие 128 бит которых являются векторными регистрами XMM. Инструкции, в отличие от SSE, принимают не два, а три регистра-операнда: два регистра-источника и один регистр-приёмник. При этом после выполнения инструкции первоначальное содержимое регистров-источников не теряется.
Почти все операции, реализованные в более ранних наборах инструкций SSE-SSE4.2, есть и в AVX/AVX2, прежде всего — арифметические. Для инструкций вроде _mm_add_epi32, _mm_madd_epi16, _mm_sub_ps, _mm_slli_epi16 и многих других имеются полностью аналогичные инструкции, но которые вдвое их производительнее.
Точных аналогов инструкций _mm_loadl_epi64 и _mm_cvtsi32_si128 (и соответствующих инструкций для вывода) в AVX/AVX2 нет. Взамен появились инструкции _mm256_maskload_epi32 и _mm256_maskload_epi64, которые загружают нужное количество 32- и 64-битных значений из памяти с использованием битовой маски.
Появились и новые инструкции _mm256_gather_epi32, _mm256_gather_epi64 (и аналогичные для чисел с плавающей запятой), которые загружают не непрерывный массив данных, а порции данных с использованием начального адреса и заданных смещений для каждой порции. Инструкции особенно полезны в случае, когда нужные данные расположены в памяти не последовательно, и требуется много операций, чтобы их извлечь и объединить.
В наборе AVX2 есть инструкции для перемешивания и перестановки данных, например _mm256_shuffle_epi32 и _mm256_alignr_epi8. Есть одна особенность, которая отличает их от других инструкций AVX/AVX2. Например, арифметические инструкции рассматривают регистр YMM как массив из 256 бит. Но указанные инструкции рассматривают YMM как два 128-битных регистра, и производят над ними операции точно таким же образом, каким их производит соответствующая инструкция SSE.
Например, регистр содержит следующие 32-битные элементы: A0, A1, A2, A3, A4, A5, A6, A7. Тогда, после выполнения
a = _mm256_shuffle_epi32(a, _M_SHUFFLE(0,1,2,3));
его содержимое станет: A3, A2, A1, A0, A7, A6, A5, A4.
Таким же образом работают и другие инструкции: _mm256_unpacklo_epi16, _mm256_shuffle_epi8, _mm256_alignr_epi8.
В AVX2 появились и новые инструкции для перестановки и перемешивания. Например, _mm256_permute4x64_epi64(__m256i, int imm) переставляет 64-битные элементы регистра таким же образом, каким mm_shuffle_epi32 переставляет 32-битные элементы.
Где получить информацию по векторным инструкциям?
Прежде всего, обратитесь к официальным сайтам производителей микропроцессоров. Intel имеет онлайн-справочник: там можно найти исчерпывающее описание интринсиков из всех наборов инструкций. Такой же справочник есть и для процессоров архитектуры ARM.
Если вы хотите изучить использование векторных инструкций на практике, обратитесь к свободным реализациям аудио- и видеокодеков. Такие проекты, как ffmpeg, VP9 и OpenHEVC используют векторные инструкции, а исходные тексты этих проектов позволяют увидеть примеры их использования.
ИСТОЧНИКИ
- https://software.intel.com/sites/landingpage/IntrinsicsGuide
- https://developer.arm.com/architectures/instruction-sets/intrinsics
- https://community.arm.com/arm-community-blogs/b/architectures-and-processors-blog/posts/coding-for-neon---part-5-rearranging-vectors
1 февраля 2022
Читать другие статьи:
Глава 1. Просто о видеокодировании
Глава 2. Межкадровое (Inter) предсказание в HEVC
Глава 3. Пространственное (Intra) предсказание в HEVC
Глава 4. Компенсация движения в HEVC
Глава 5. Постпроцессинг в HEVC
Глава 6. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 1
Глава 7. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 2
Глава 8. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 3
Глава 9. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 4
Глава 10. Контекстно-адаптивное двоичное арифметическое кодирование. Часть 5
Глава 11. Немного о DCT
 Автор
Автор
Дмитрий Фарафонов
Инженер Elecard. Занимается оптимизацией аудио- и видеокодеков, а также программ для обработки аудио- и видеосигналов с 2015 года.